Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings
Por um escritor misterioso
Last updated 02 julho 2024
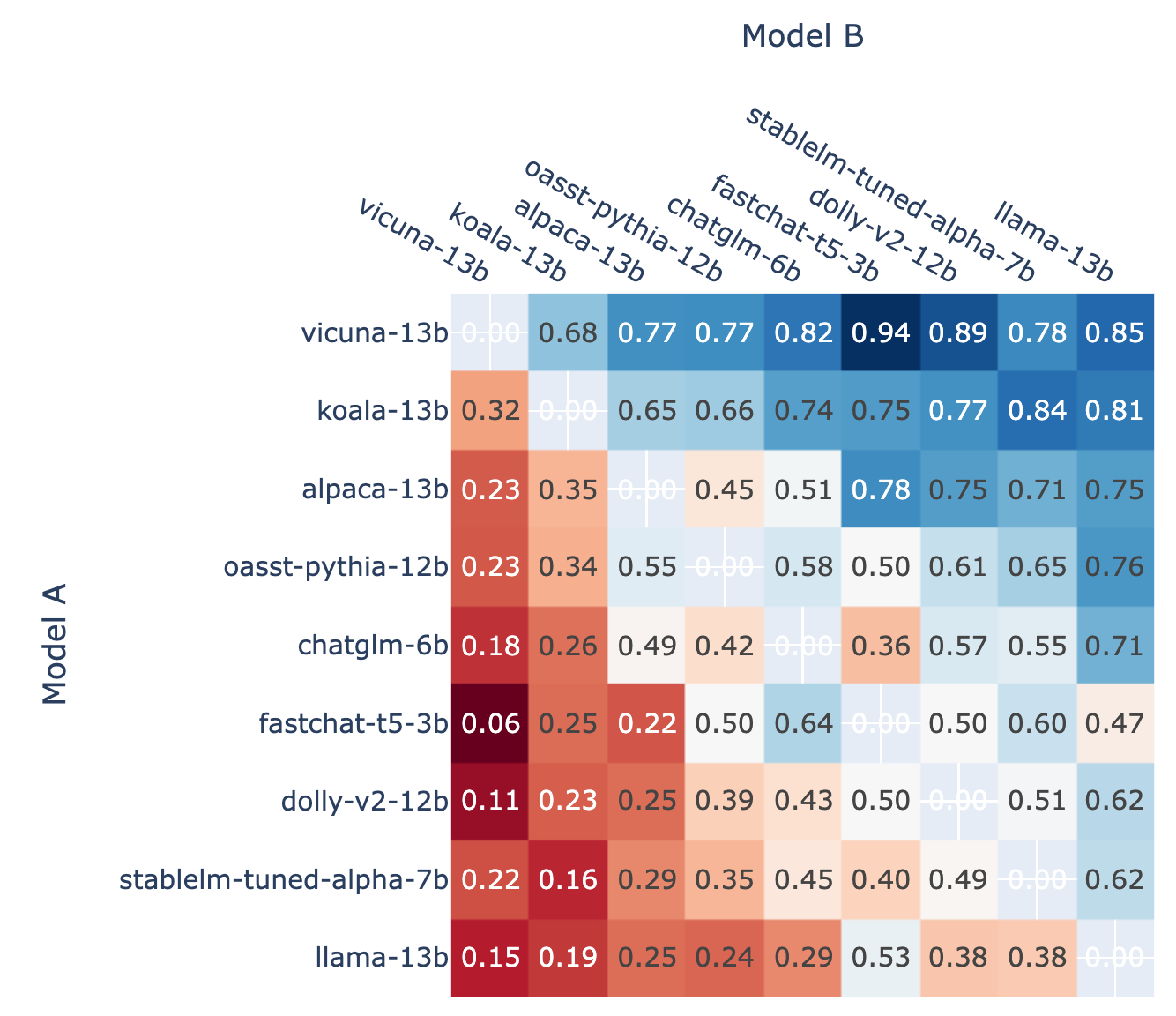
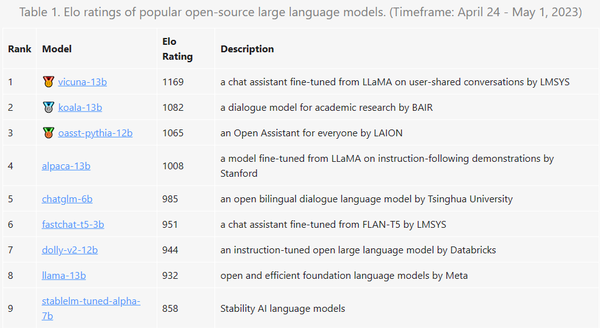
lt;p>We present Chatbot Arena, a benchmark platform for large language models (LLMs) that features anonymous, randomized battles in a crowdsourced manner. In t

Sponsor @merrymercy on GitHub Sponsors · GitHub
目前大语言模型的评测基准有哪些? - 博而不士的回答- 知乎

Chatbot Arena (聊天机器人竞技场) (含英文原文):使用Elo 评级对LLM进行基准测试-- 总篇- 知乎
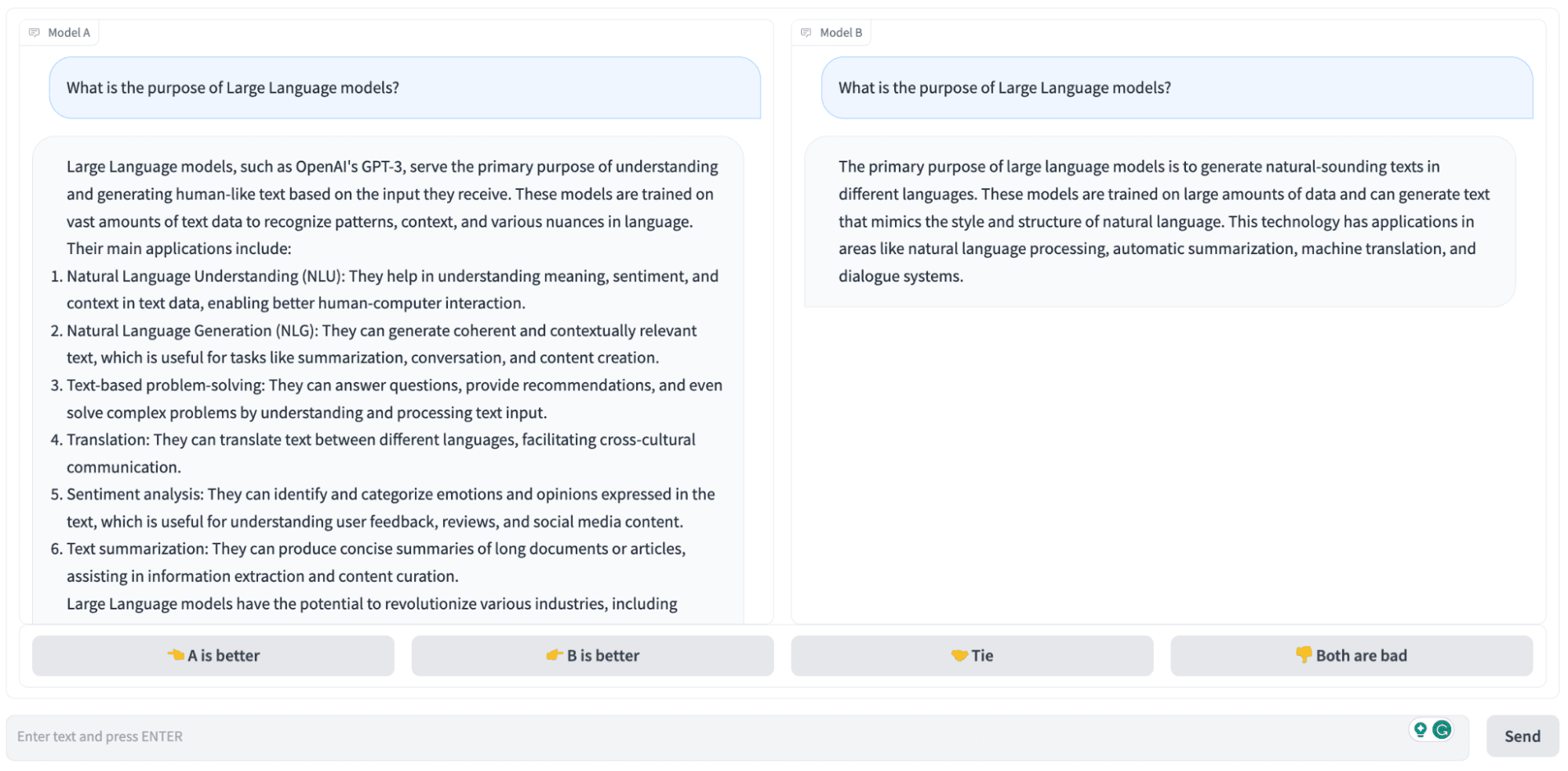
Chatbot Arena: The LLM Benchmark Platform - KDnuggets

Knowledge Zone AI and LLM Benchmarks

GPT-4-based ChatGPT ranks first in conversational chat AI benchmark rankings, Claude-v1 ranks second, and Google's PaLM 2 also ranks in the top 10 - GIGAZINE
Chatbot Arena - a Hugging Face Space by lmsys
Large Language Model Evaluation in 2023: 5 Methods

PDF) LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
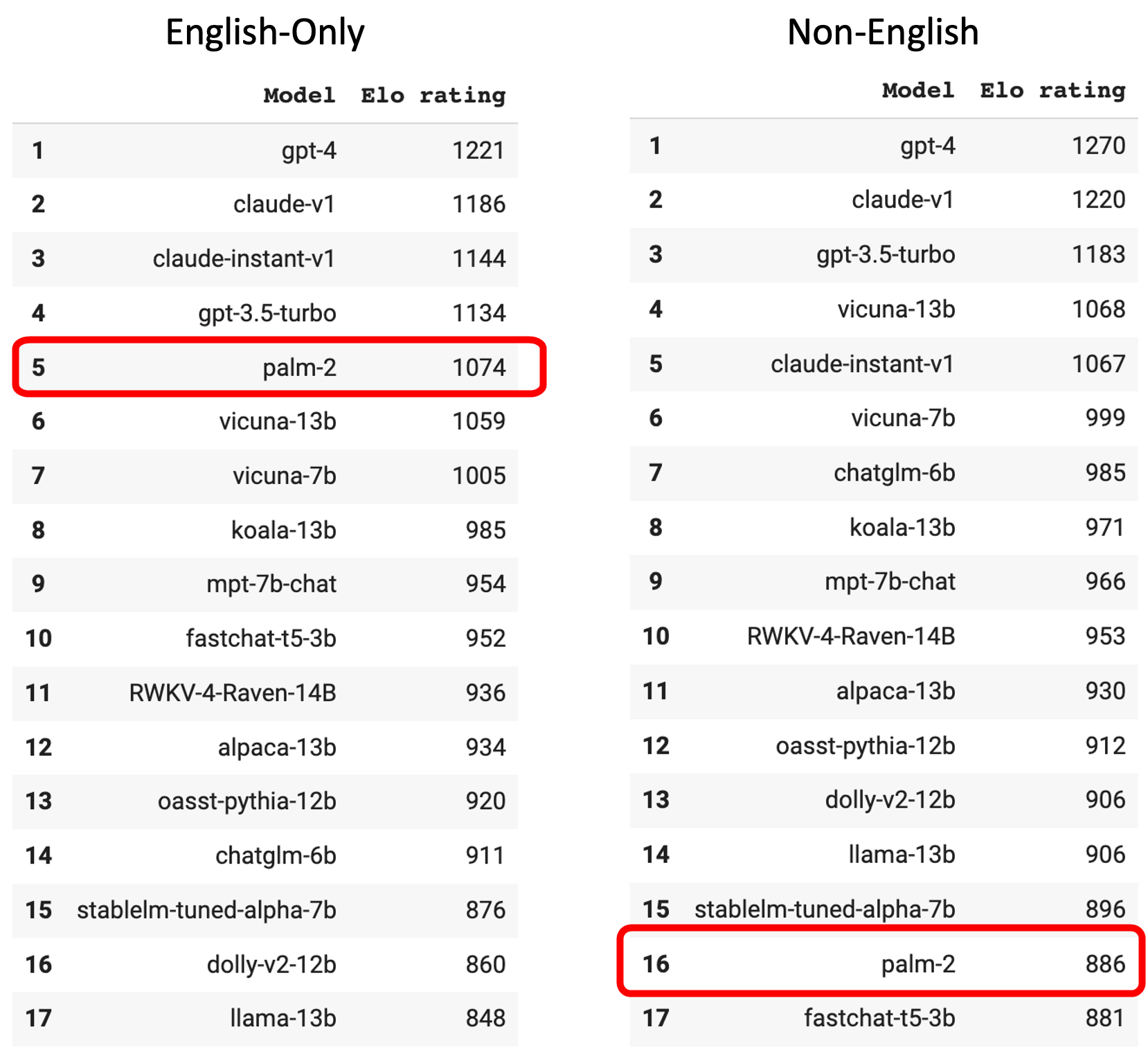
GPT-4-based ChatGPT ranks first in conversational chat AI benchmark rankings, Claude-v1 ranks second, and Google's PaLM 2 also ranks in the top 10 - GIGAZINE

AI News (15th May 2023)
Vinija's Notes • Primers • Overview of Large Language Models
LLM Benchmarking: How to Evaluate Language Model Performance, by Luv Bansal, MLearning.ai, Nov, 2023

PDF) The Costly Dilemma: Generalization, Evaluation and Cost-Optimal Deployment of Large Language Models

Around the Block podcast with Launchnodes: 101 on Solo Staking : r/ethereum
Recomendado para você
-
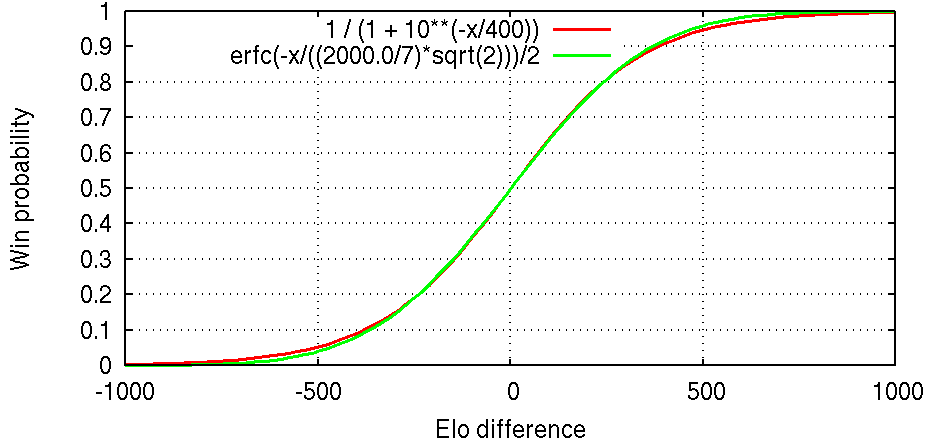 Elo Win Probability Calculator02 julho 2024
Elo Win Probability Calculator02 julho 2024 -
Chess Ranking System: A Complete Guide02 julho 2024
-
 Chess Ratings Explained – Chess Armory02 julho 2024
Chess Ratings Explained – Chess Armory02 julho 2024 -
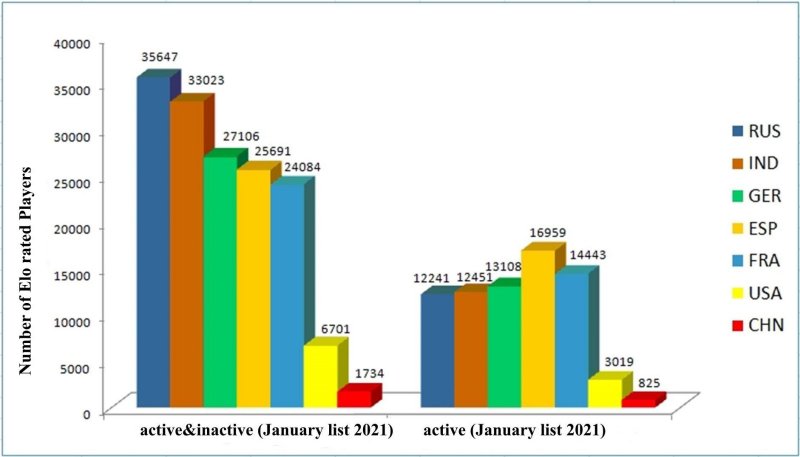 A look at the Elo ratings in the year 202102 julho 2024
A look at the Elo ratings in the year 202102 julho 2024 -
 Better Than Ratings? 's New 'CAPS' System02 julho 2024
Better Than Ratings? 's New 'CAPS' System02 julho 2024 -
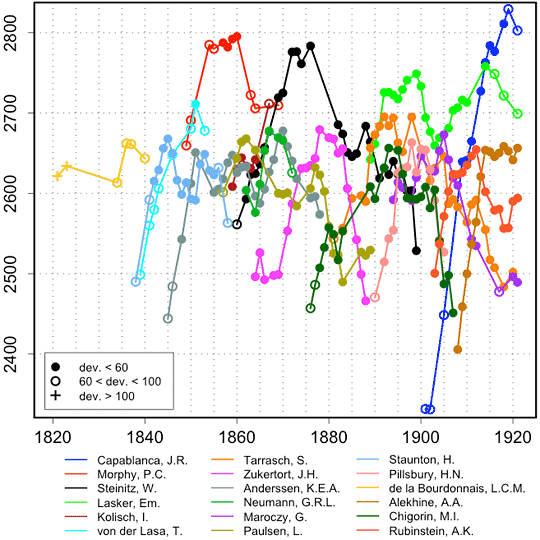 Historical Chess Ratings – dynamically presented02 julho 2024
Historical Chess Ratings – dynamically presented02 julho 2024 -
 The Chess Rating System Explained02 julho 2024
The Chess Rating System Explained02 julho 2024 -
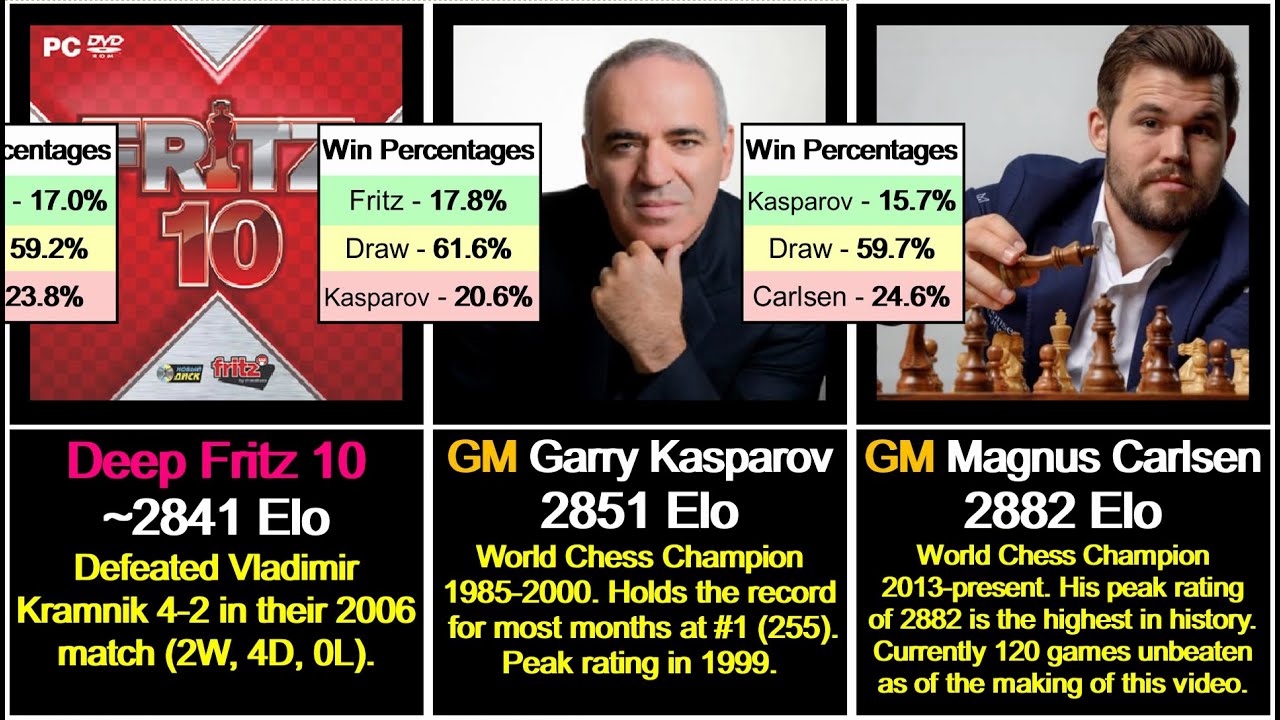 Chess Elo Rating Comparison - Magnus Carlsen, Agadmator, Stockfish and more!02 julho 2024
Chess Elo Rating Comparison - Magnus Carlsen, Agadmator, Stockfish and more!02 julho 2024 -
 Chess Ranking System: Every Thing You Need To Know - Henry Chess Sets02 julho 2024
Chess Ranking System: Every Thing You Need To Know - Henry Chess Sets02 julho 2024 -
 Why are men ranked higher in chess than women? It has to do with02 julho 2024
Why are men ranked higher in chess than women? It has to do with02 julho 2024

você pode gostar
-
 Garena Bed Wars 1.9.1.5 (arm-v7a) APK Download by GARENA GAMES PRIVATE LIMITED - APKMirror02 julho 2024
Garena Bed Wars 1.9.1.5 (arm-v7a) APK Download by GARENA GAMES PRIVATE LIMITED - APKMirror02 julho 2024 -
 Parking Games 🕹️ Play on CrazyGames02 julho 2024
Parking Games 🕹️ Play on CrazyGames02 julho 2024 -
 Yuusha Shoukan ni Makikomareta kedo, Isekai wa Heiwa deshita Merch02 julho 2024
Yuusha Shoukan ni Makikomareta kedo, Isekai wa Heiwa deshita Merch02 julho 2024 -
 The Best Animated Film Characters - Empire02 julho 2024
The Best Animated Film Characters - Empire02 julho 2024 -
 Day in the life02 julho 2024
Day in the life02 julho 2024 -
![Kirby Super Star Allies Ultra [Kirby Star Allies] [Works In Progress]](https://images.gamebanana.com/img/ss/wips/62566b7d84973.jpg) Kirby Super Star Allies Ultra [Kirby Star Allies] [Works In Progress]02 julho 2024
Kirby Super Star Allies Ultra [Kirby Star Allies] [Works In Progress]02 julho 2024 -
 Meu Livro Quebra-Cabeça: Animais De Estimação02 julho 2024
Meu Livro Quebra-Cabeça: Animais De Estimação02 julho 2024 -
 Como jogar Naruto online pelo celular em 2023?02 julho 2024
Como jogar Naruto online pelo celular em 2023?02 julho 2024 -
 Persona®5 Royal Ultimate Edition02 julho 2024
Persona®5 Royal Ultimate Edition02 julho 2024 -
 como fazer combo com a magma no blox fruit02 julho 2024
como fazer combo com a magma no blox fruit02 julho 2024