RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 05 julho 2024

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.

deep learning – Severely Theoretical

Memory for Lean Reinforcement Learning.pdf

PDF) A Review for Deep Reinforcement Learning in Atari:Benchmarks, Challenges, and Solutions

PDF) Tensor Implementation of Monte-Carlo Tree Search for Model-Based Reinforcement Learning

EfficientZero: Mastering Atari Games with Limited Data (Machine Learning Research Paper Explained)
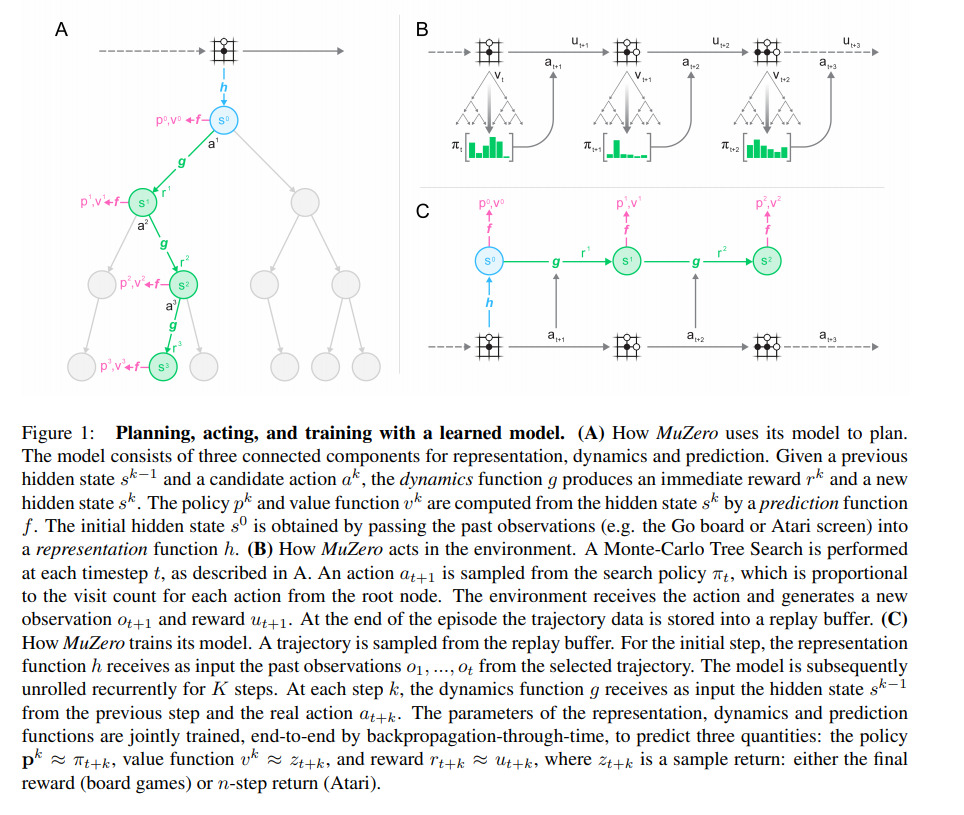
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors

Mastering Atari Games with Limited Data – arXiv Vanity
RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari

Mastering Atari Games with Limited Data – arXiv Vanity
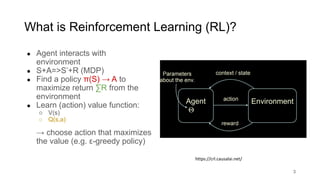
Memory for Lean Reinforcement Learning.pdf
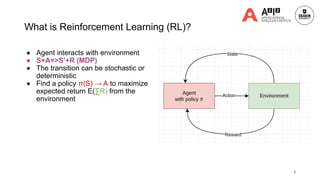
Memory-based Reinforcement Learning
Recomendado para você
-
The future is here – AlphaZero learns chess05 julho 2024
-
 AlphaZero: Checkmate - History of Data Science05 julho 2024
AlphaZero: Checkmate - History of Data Science05 julho 2024 -
 Acquisition of chess knowledge in AlphaZero05 julho 2024
Acquisition of chess knowledge in AlphaZero05 julho 2024 -
Reimagining Chess with AlphaZero on Vimeo05 julho 2024
-
Google Deepmind's AlphaZero Chess Engine Makes Inhuman Knight Sacrifice AlphaZero is back with dazzling new games from a fresh 1,000 game chess match against Stockfish! 🤯 Don't miss this brand new05 julho 2024
-
 AI learns to rule the quantum world05 julho 2024
AI learns to rule the quantum world05 julho 2024 -
 AlphaZero AI beats champion chess program after teaching itself in four hours, DeepMind05 julho 2024
AlphaZero AI beats champion chess program after teaching itself in four hours, DeepMind05 julho 2024 -
 AlphaZero – a generic game-beater Chess Rising Stars London Academy Shop05 julho 2024
AlphaZero – a generic game-beater Chess Rising Stars London Academy Shop05 julho 2024 -
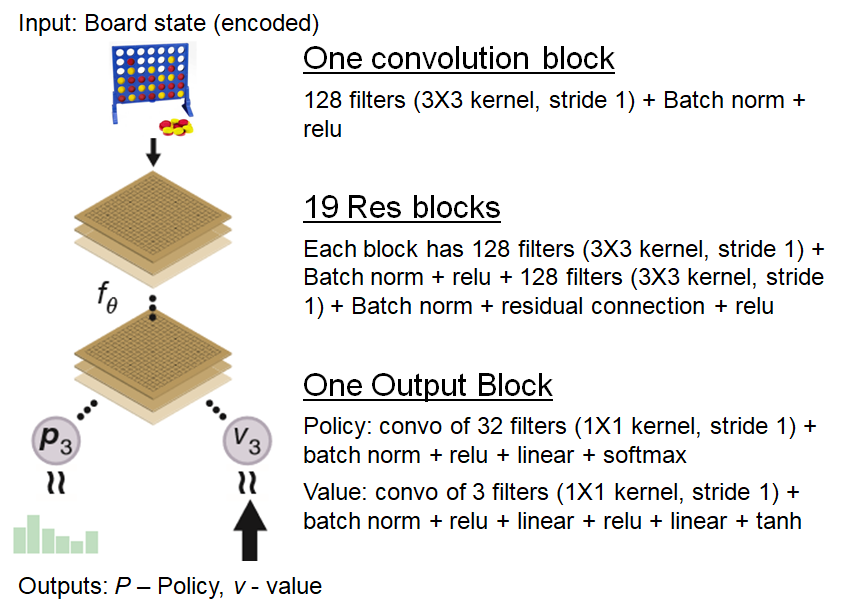 From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh05 julho 2024
From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh05 julho 2024 -
 AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x1905 julho 2024
AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x1905 julho 2024



você pode gostar
-
 Emilia/Image Gallery, Re:Zero Wiki, Fandom05 julho 2024
Emilia/Image Gallery, Re:Zero Wiki, Fandom05 julho 2024 -
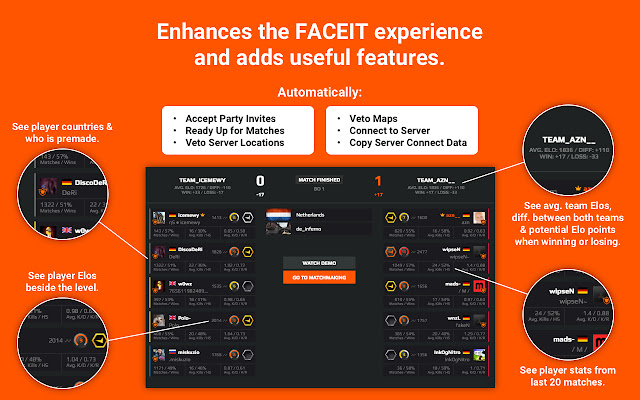
Repeek (formerly FACEIT Enhancer)05 julho 2024
-
Author Brandon Sanderson's Jaw-Dropping Kickstarter Raises Questions05 julho 2024
-
 Tati Gabrielle shares what it's actually like being in Joe's box05 julho 2024
Tati Gabrielle shares what it's actually like being in Joe's box05 julho 2024 -
:upscale()/2018/03/29/911/n/1922283/tmp_dM3dS0_a6e71f98a623eec9_MCDAVIN_EC018.jpg) Who Does Letitia Wright Play in Ready Player One?05 julho 2024
Who Does Letitia Wright Play in Ready Player One?05 julho 2024 -
 Watch Dogs: Legion Achievement Guide & Road Map05 julho 2024
Watch Dogs: Legion Achievement Guide & Road Map05 julho 2024 -
 The meme collector is here, please donate one of your all time favorites - 9GAG05 julho 2024
The meme collector is here, please donate one of your all time favorites - 9GAG05 julho 2024 -
 Selling Permanent Dough (Blox Fruit), Video Gaming, Gaming Accessories, In-Game Products on Carousell05 julho 2024
Selling Permanent Dough (Blox Fruit), Video Gaming, Gaming Accessories, In-Game Products on Carousell05 julho 2024 -
 Need For Speed Rivals Ps3 Game Digital PSN - ADRIANAGAMES05 julho 2024
Need For Speed Rivals Ps3 Game Digital PSN - ADRIANAGAMES05 julho 2024 -
 Jogo Battlefield 2042 PS4 - Electronic Arts - Battlefield - Magazine Luiza05 julho 2024
Jogo Battlefield 2042 PS4 - Electronic Arts - Battlefield - Magazine Luiza05 julho 2024